Entities: with BOARD 11 when defining a new entity you no longer need to define the max item number, this property and related settings no longer exist.
Cubes: with BOARD 11 when defining a cube you only need to define the entities by which it is structured. You no longer need to define sparsity and secondary versions.
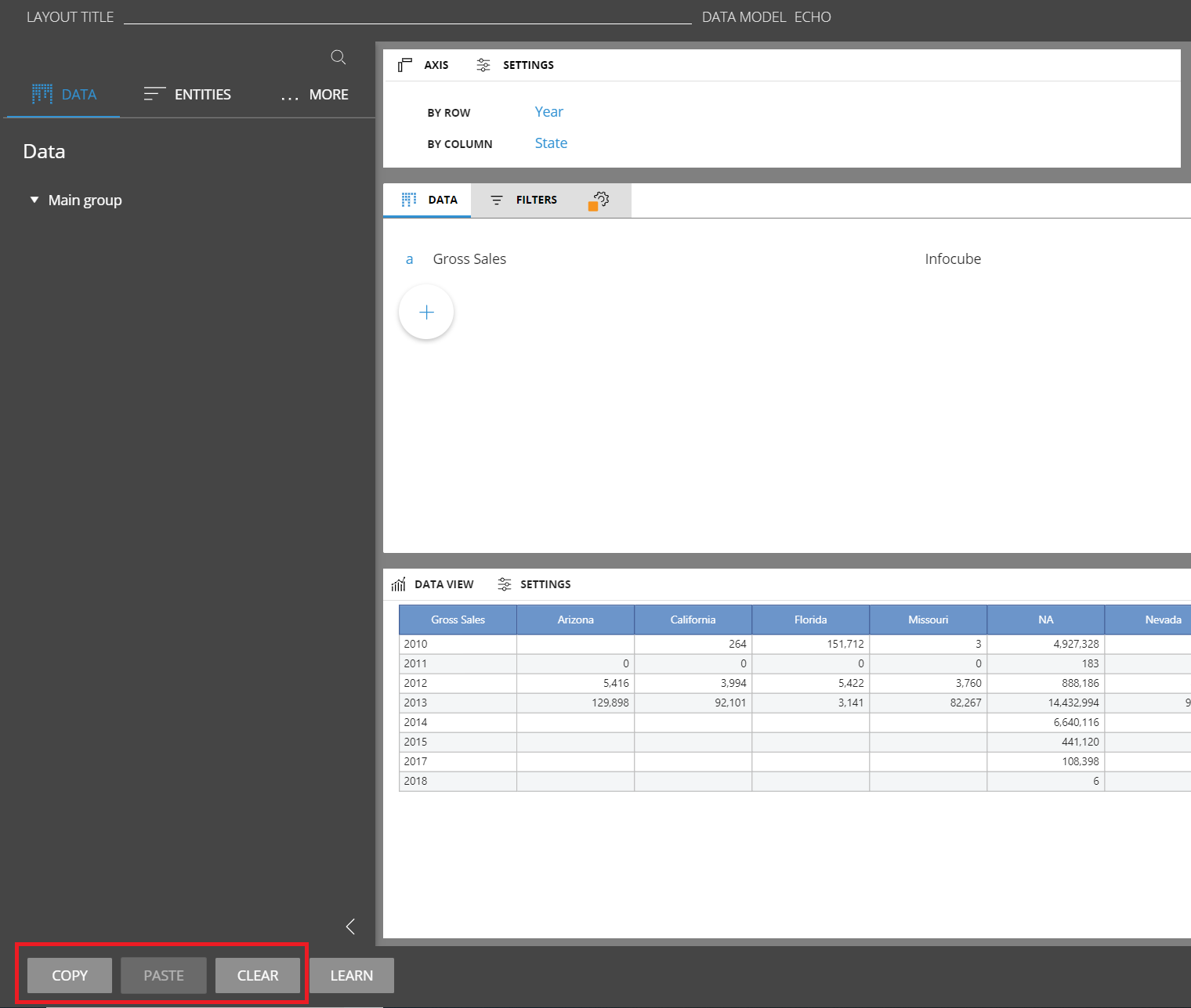
It is now possible to copy and paste the layout configuration from the web layout designer. Once a layout is opened there are new buttons available in the editor: Copy, Paste, Clear.
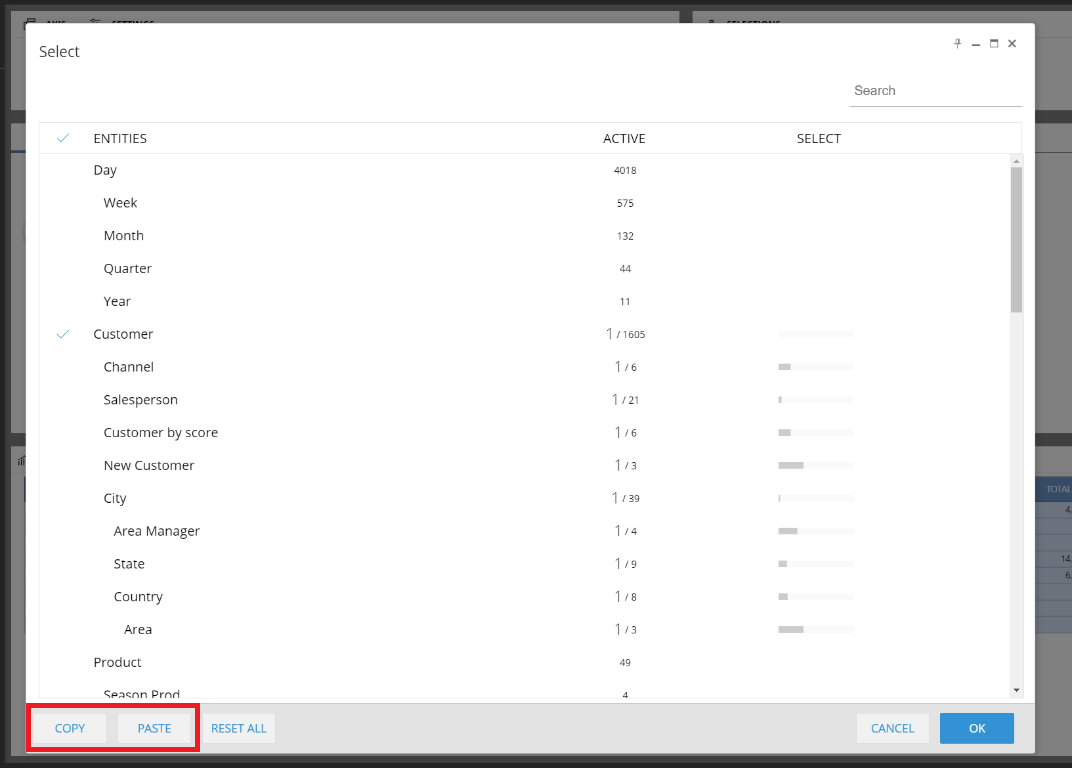
The same function has been added for the Select. So the copy and paste buttons are available on the web select window.
A new set of shortcuts has been introduced in different sections of the web designer. Below the list of the shortcuts:
Screen Designer:
CTRL+C -> copy toolbox
CTRL+V -> paste toolbox
CTRL+S -> save
CTRL+Z -> undo
CTRL+Y -> redo
DELETE -> delete toolbox
F5 -> refresh layout
F4 -> switch design play
Rules:
CTRL+C -> copy rule
CTRL+V -> paste rule
CTRL+A -> select all
ESC -> deselect cell, lost focus
DELETE -> delete rule
Layout editor:
CTRL+C -> copy layout
CTRL+V -> paste layout
F5 -> refresh preview
Procedure steps:
CTRL+C -> copy toolbox
CTRL+V -> paste toolbox
Select window:
CTRL+C -> copy select
CTRL+V -> paste select
The aggregation functions are available in the layout editor on the block settings. These functions replace and enhance the MXC cube functionality.
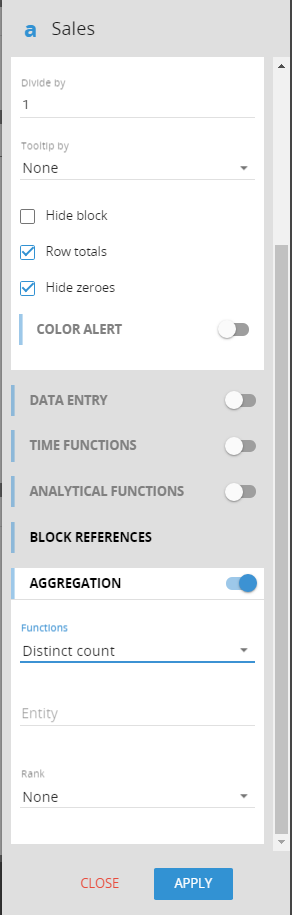
There are three aggregation functions:
Sum: Default sum function
Distinct count: Returns the distinct item count for the entity selected on every cell. For example, in a report by customer and month distinct count of products will return the distinct number of products sold for that customer on that month
Average: Returns the average on a given entity instead of the sum, average = sum/distinct count
The user can filter the counting entity members with a rank. For example, it can restrict the sum only on the top 10 products or on the flop n products or restrict the analysis only on a given range of products in terms of percentiles (i.e. from 20% to 80%).
It is possible to configure the NEXEL layer directly from the web application. The NEXEL can be enabled from the layout editor on the block configuration settings. When enabled it is also possible to select the formula type: single formula or deepest entity formula.
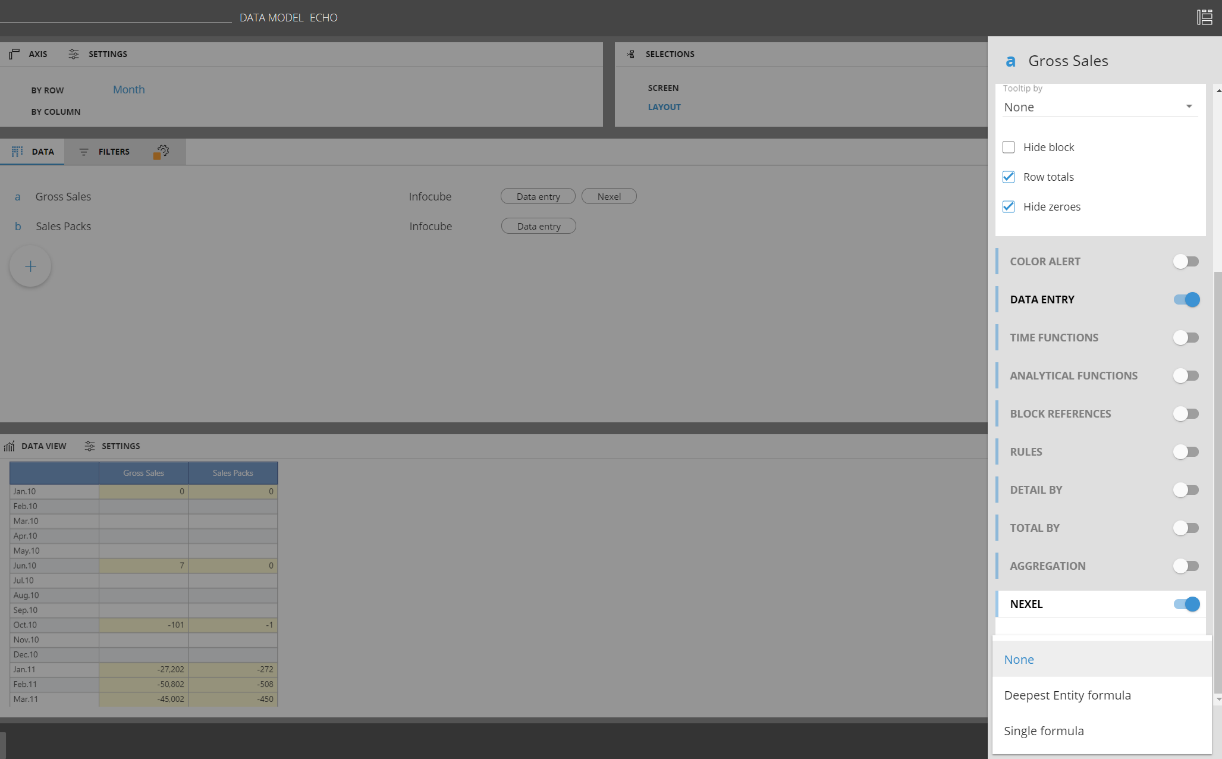
Once enabled, the configuration is done from the sliding toolbar of the dataview:
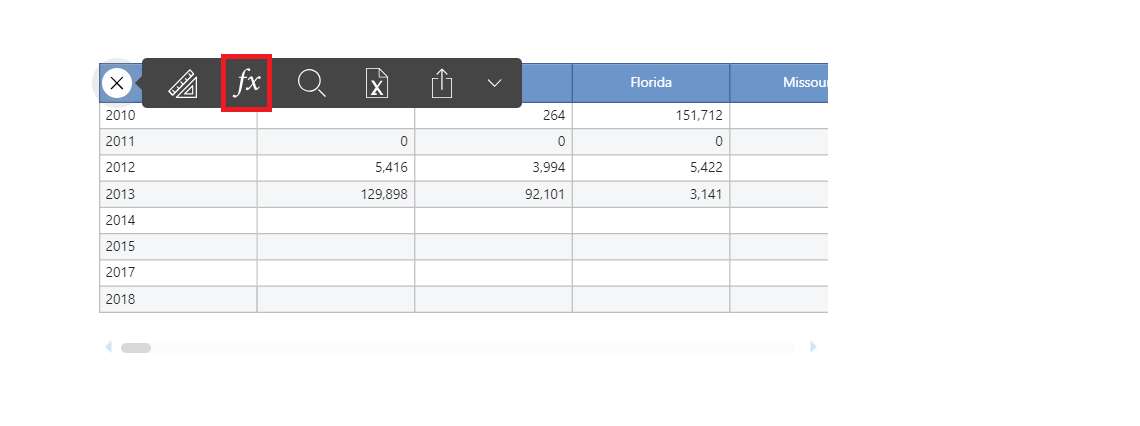
Clicking on the fx button, it will open the configuration window where it is possible to define the formula and set-up all the nexel options needed.
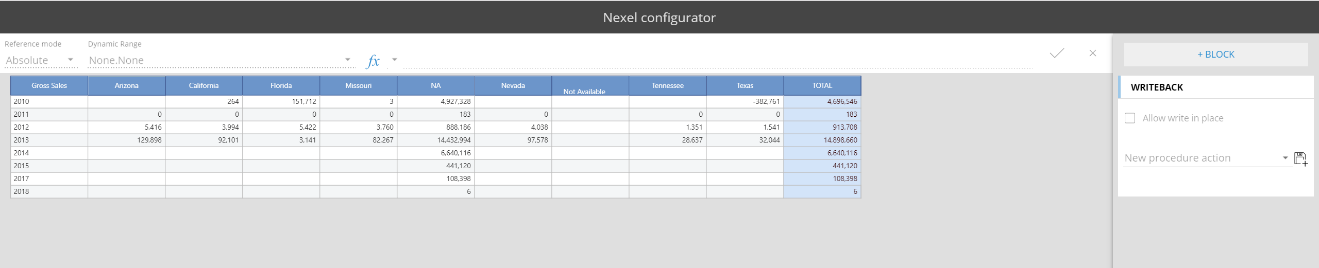
If you want to read more about the NEXEL you can go HERE.
The Block Format Editor has been added to the web designer. The editor is accessible when the screen is in design mode, selecting the dataview, on the right side configuration panel.
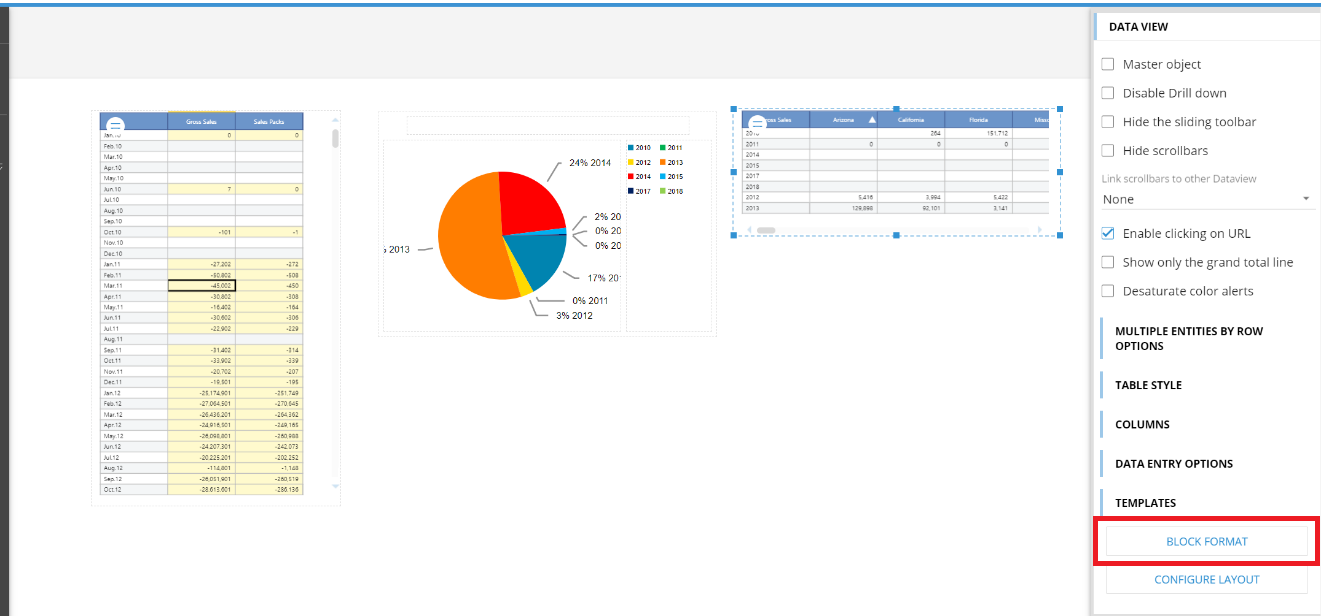
Clicking on Block Format it will open the configuration window where it is possible to customize the block appearance on the dataview.

If you want to read more about the Block Formatting you can go HERE.
The Row Format Editor has been added to the web designer. The editor is accessible from the data model designer, through the Format tile.

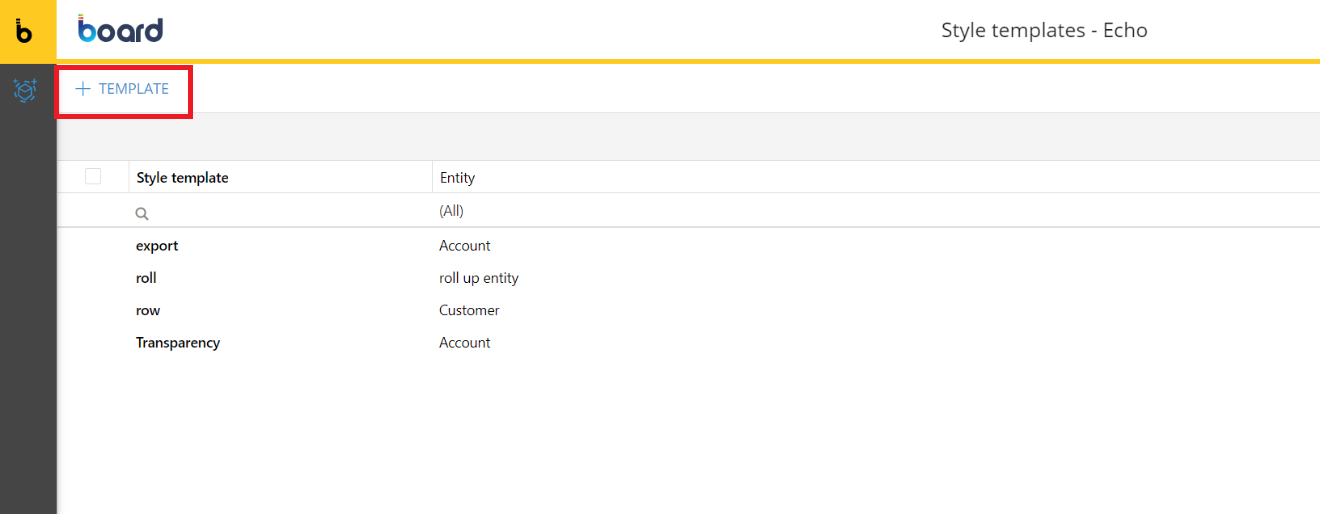
Clicking on +TEMPLATE it is possible to define and design your row templates through the below configuration panel:
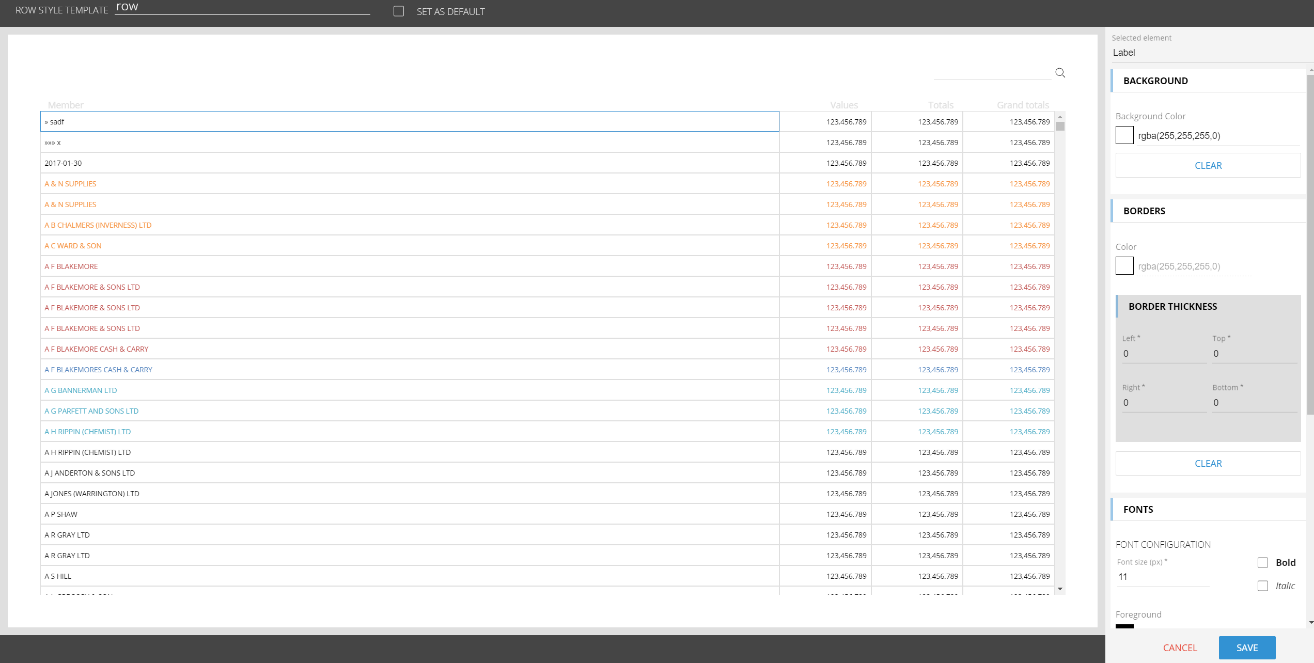
If you want to read more about the Row Formatting you can go HERE.
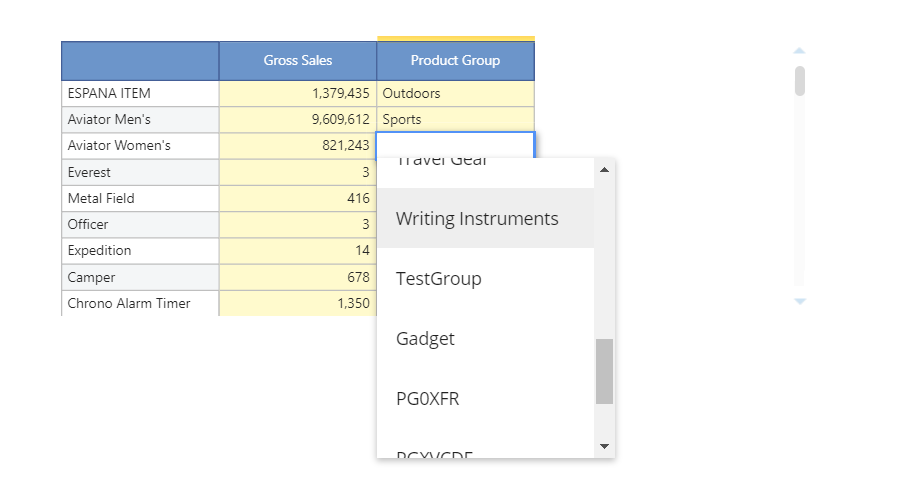
It is now possible to set up an entity as suggested values in a dataview column as a drop down list:
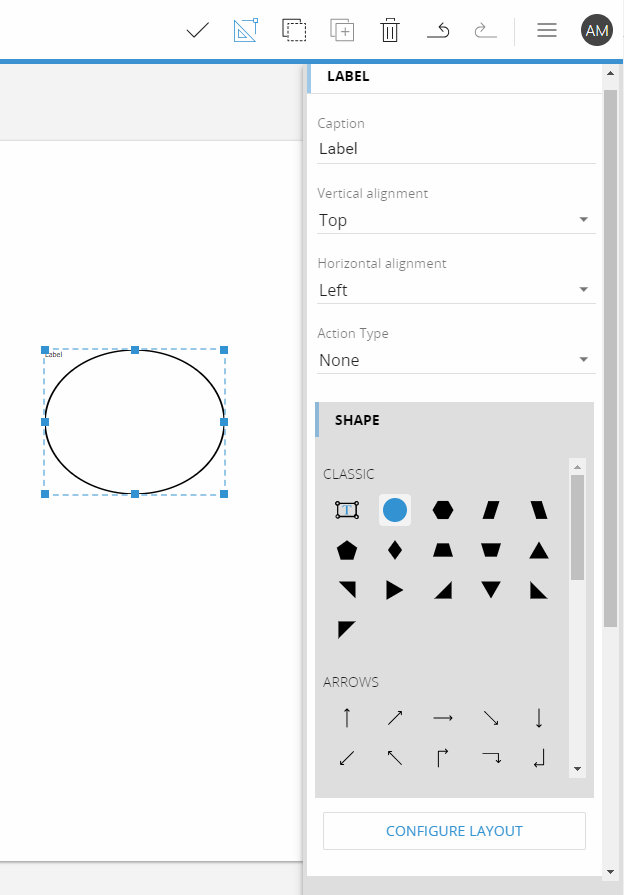
the object label can now be configured with several shapes
A new flag has been introduced in the Rules definition: "Authorize editing by power user". If an admin creates a rule, it can give the permissions to the power users to enable that specific rule.
The DataFlow calculations are now by default executed only on the non-null cells of the DataFlow Layout. The Dataflow will process the formula for each combination of the members of the entities that are in the structure of the target cube. Not every potential combination, but only the ones that have a non-zero value on at least one of the Dataflow blocks, each combination is called a tuple.
It is possible to extend or reduce the range of processed tuples through the Calculation Domain setting which has been newly introduced.
The domain can be limited or expanded:
Limited to the tuples that are non-zero in every block.
Limited to the tuples that are non-zero in a chosen cube in the Datamodel.
It can be expanded evaluating also the combinations that are zero in the configuration layout for all the members of a given set of entities of the target cube.
The Calculation Domain allows to explicitly define the range of cube cells that are processed therefore simplifying the definition of Dataflow regardless of the structure of cubes and at the same time optimizing performance by processing only the desired portion of cube.
It is now possible to define within a Procedure one or more Temporary Cubes that are created and used only locally within the scope of the Procedure. Temporary Cubes are created at the start of the execution of the Procedure and destroyed when the Procedure ends. By nature, Temporary Cubes only occupy RAM during the course of the execution of the Procedure and are never physically stored to disk.
Temporary Cubes can be used as standard Cubes in Dataflow calculations (as target or source of a Dataflow). In the future, we plan to extend the use of Temporary Cubes in selections, extract and other cube-related actions.
Temporary Cubes are defined in the procedure main property panel, as shown in the image below.
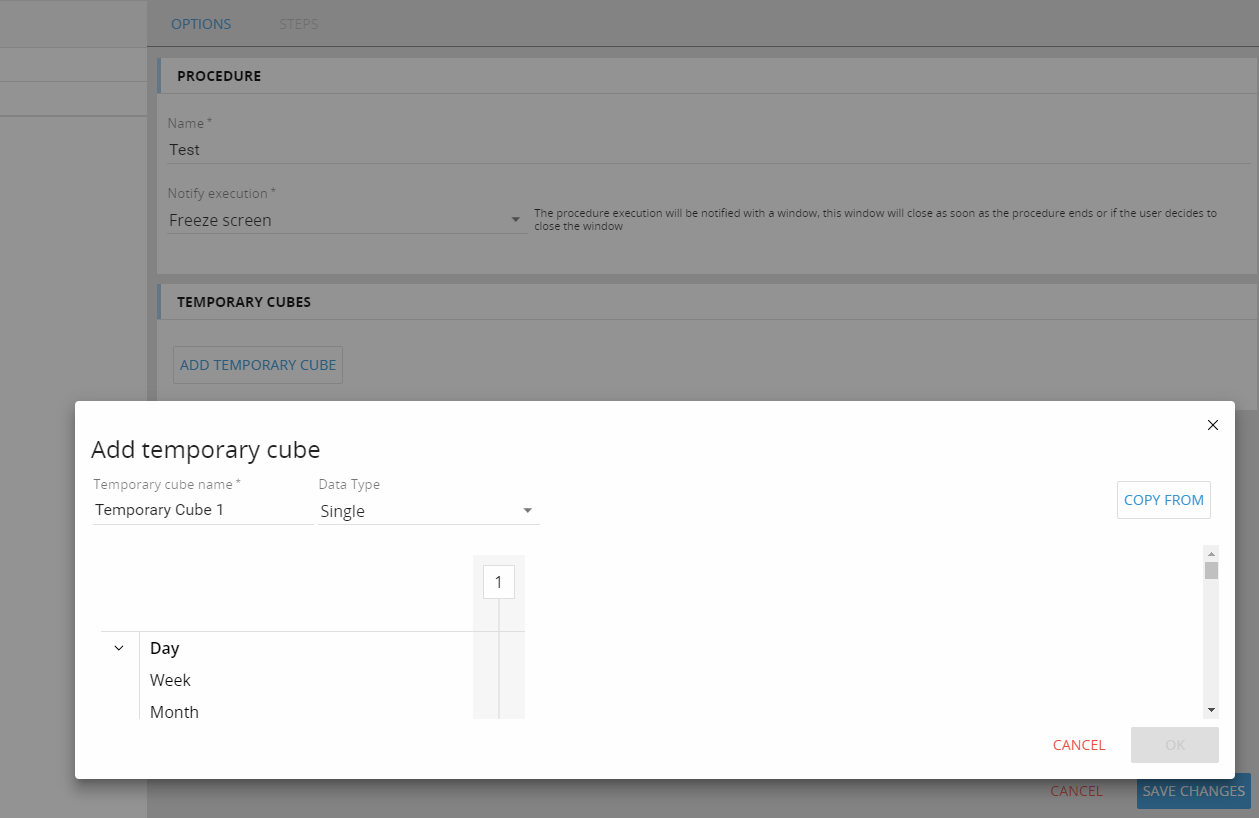
It is possible to define the Cube name, the data type and its structure (in terms of dimensions).
These Cubes are allocated to memory only during the execution of the Procedure and are deleted at the procedure completion. Temporary Cubes can be used only within the Procedure where they are defined, they are not visible from the Cubes list of the Data model. Every Procedure invocation allocates a different Temporary Cube, therefore two different users that launch the same Procedure will not affect each other, but they will remain completely isolated.
A Broadcasting action can be invoked from a Procedure:
The Learning function allows to optimize performance of a Layout by automatically generating best possible pre-aggregated version that improves performance on the layout. To activate learning mode the license level must be developer with administrator rights on the database.
Learning might take some time to be executed. At the end of the learning mode the layout performance will be optimized. Learned cube versions can be deleted from the DB manager. Those versions are auto-aligned versions.
The Learn function is available on the layout editor.
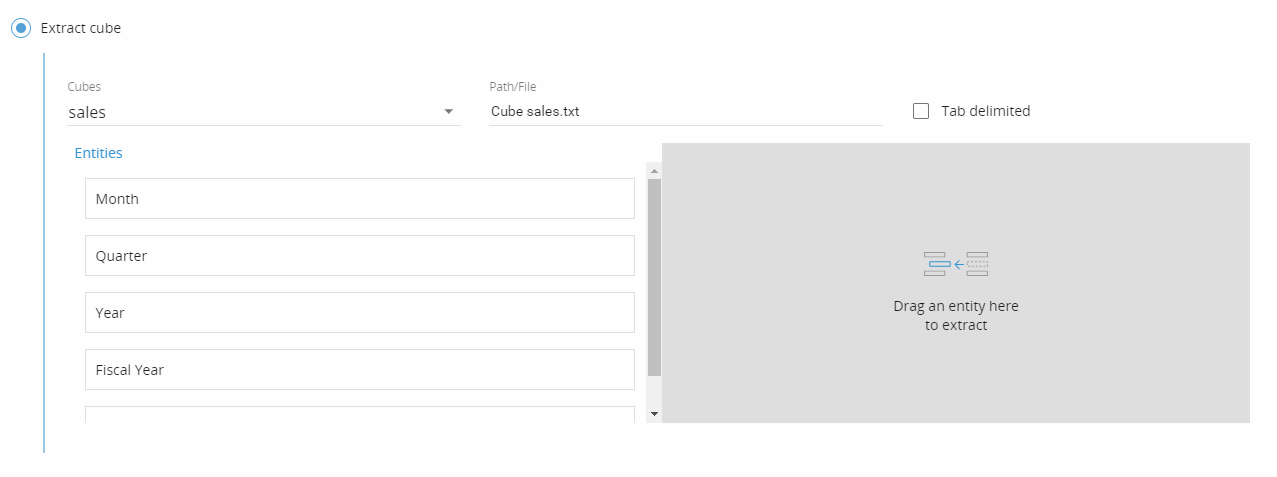
The extract cube procedure step has been enhanced. It is now possible to define the structure of the exported file (entities and order). Below the interface available in the procedure designer:
A malfunction on the print to word of a layout with a customized title has been fixed.
A malfunction in the web interface where it is possible to populate the custom time entities has been fixed.
The Screen Header Title is now translated in the correct way when the localization is enabled on the web application.
The marker values on the Pie Chart Object can now be customized in terms of number of digits.
The change mask size option setting has been reviewed and improved.
A malfunction on the display of RTF cubes content in the Dynawrite object has been fixed.
A malfunction on the export to Excel from a drill-down window has been fixed.
A malfunction related to the time zone settings and the calendar object has been fixed.
The chart marker values are now shown according to the user regional settings.
A malfunction on the Export to excel from drill down has been fixed
Broadcasting: SMTP server with SSL is now supported
Version 11 introduces a full web HTML5 client. The windows client has been dismissed. Capsules that are created from the web client have a new format: ".bcps". The old ".cpsx" capsule can be still used in play mode in the old format. Old capsule in ".cpsx" need to converted into the new ".bcps" format to be used in edit mode on the web client (a common web browser). The migration process is automatic and documented HERE. The system will retain a copy of the capsule in the old format renaming it with the "(BKP) tag in the capsule name.
Database migration
The following activities must be performed to migrate a database to BOARD 11:
Before upgrading to 11, open the database you want to migrate using your current version (BOARD 10.x or earlier)
Extract All Cubes on all the selected databases. This will generate a set of CSV files in your Board\Dataset\database_name folder.
Clear All Cubes on the selected databases
Now install version 11:
if you're a Cloud Customer: submit a ticket to BOARD Support in order to obtain version 11 on the desired sandbox environment. Our cloud team will perform the deployment and notify you when ready
open the database with the new version 11 and confirm the database migration. If you have extracted the cubes content in the default path, the migrate process will automatically reload the cubes. If you extracted the cubes content in a custom path, the migration will just convert the database then an additional reload all cubes step need to be configured and run, pointing to the custom extraction path.
Important Notice
The MXC cubes won't be available in the migrated version of the Database. The MXC cubes can be easily replaced by the aggregation functions. If you have any BigData cubes defined in the database, you need to change the cube type to the standard cube one before the database migration. The H-OLAP cubes (MOLAP and ROLAP versions) just keeps the most detailed version after the migration.