予測的分析
バージョン9以降、BOARDは、予測の際にユーザを支援する新しい数学的エンジンを提供します。
このツールでは、履歴データに依存して自動的に調整される数学的モデルのアプリケーションを介して、履歴データに基づく自動的な予測を計算します。
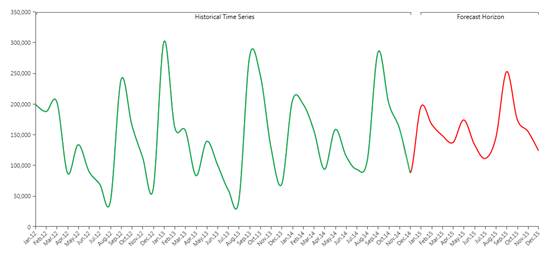
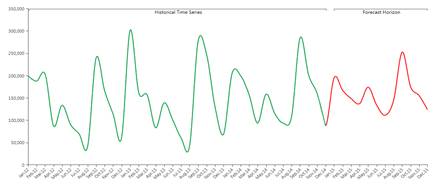
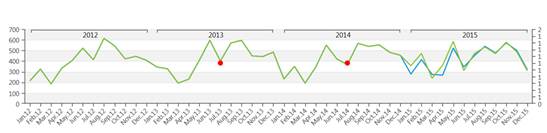
上記の図では、予測的分析機能(赤色)を介して、将来に対して予測された履歴データ(緑色)の例が示されています。
予測的分析ツールの自動的な特性を介して、豊かな柔軟性が維持されるため、ユーザは予測をさらに精密にして、予測シナリオに情報を追加することが出来ます。 実際に、ユーザは履歴時系列以外に、後半で詳細を説明する他の数量及びパラメータをビームにフィード出来ます。 まず、システムは履歴データに適用するのにどれが最適なモデルなのかを理解し(学習フェーズ)、次に、モデルを将来に対してプッシュします(予測フェーズ)。
1.1 基本概念
このセクションでは、分析インターフェイスを詳細に理解して正しい方法で使用するために必要な、一連の概念を一覧で記載します。
1.1.1 フロー
予測分析シナリオを実行すると、一部のソースキューブにおいて、エンジンが以下を実行します。
· 時系列の検出
· 各時系列に[中止(Discontinued)]、[断続(Intermittent)]、又は[円滑(Smooth)]のラベル表示
· 各系列の先頭からゼロを削除することによる時系列のトリミング
· 競合を介した各系列に対する最適なモデルの識別
· 異常値の識別
· 有用な共変量の検出、外因性の共変量の適用、及びモデルを改善しない共変量の破棄
· 将来的な再利用を目的としたモデルのシリアル化
この部分は、学習の部分であり、完了するとシステムはモデルを将来的な値(予測期間)へ単に適用して、様々なインジケータを出力します。この部分は予測の部分です。
次に、上記の全ての概念(時系列、異常値、共変量…)を1つずつ説明します。このプロセス全体は自動的であり、ユーザにはそのアクションが表示されず、出力のみが表示されることに注意してください(下記を参照)。
1.1.2 時系列
一般的に、時系列は時間エンティティにわたる値のリストです(日、週、月)。
市、製品、及び月で構成されたキューブ(観察されるキューブ)内でデータを予測する必要があると仮定してみましょう。ただし、地域、製品グループ、及び月のレベル(対象のキューブの構造)で予測を実行する必要があるとします。 時系列は全て、ソースキューブ内の地域と製品グループの非ゼロの組み合わせです。 言い換えると、レイアウト内で製品グループを行ごとに、月を列ごとに配置する場合、各行は時系列を示します。
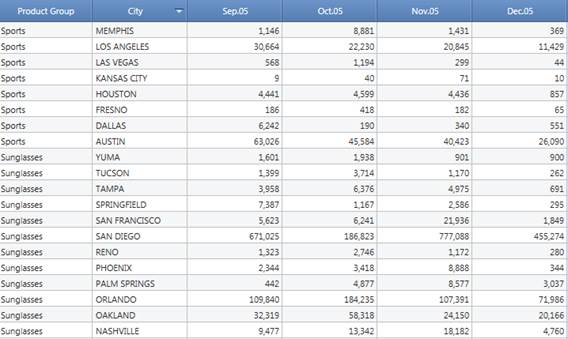
時系列の数は、粒度と名前が付けられています。
1.1.3 時系列のラベル表示
時系列には、[中止(Discontinued)]、[断続(Intermittent)]、又は[円滑(Smooth)]の3つのタイプがあります。
[中止(Discontinued)]
時系列が決定的にゼロの場合(最終年のデータが常にゼロ)、時系列は中止されます。

[断続(Intermittent)]
時系列が頻繁にゼロであっても、一部の期間において値が存在する場合、時系列は断続的です。 例えば、ヨットを販売している場合、ヨットを毎月販売する可能性は低く、ヨットを年に2回販売する可能性が高いと考えられます。 このような系列は断続的です。 技術的には、系列内の2つの非ゼロの値間において、(期間内に)経過した中位時間を計算します。この値が1.3よりも大きい場合、系列は断続的です。
[円滑(Smooth)]
ほぼ各期間に値が含まれた系列は、円滑として定義されます。基本的に、断続あるいは中止ではない全ての系列が円滑です(2つの非ゼロの値間の経過した期間内の中位時間が1.3より小さくなります)。
1.1.4 モデル
中止の時系列は、将来においてもゼロであると仮定されるため、この種の系列のモデルは、各期間で単にゼロ値です。 断続の系列では、予測に Croston-SBAモデルを使用します。 このモデルの特性により、将来的な予測は各期間において定数になります。

円滑の系列の場合は、状況がやや複雑になります。 時系列のモデルは、Idsi-ARXと名前が付けられています。 このモデルは、ARIMAファミリの一部です。 ARIMAは、競合を介して時系列に適合します。系列は、期間中での長さが0.75に切り取られ、最初の部分はARIMAを計算するために使用され、残りの部分はベンチマークとして使用されます。 最適なモデルが選択されます。 また、競合においては、永続的な予測変数(常に系列の最後の値)及び季節的な予測変数(基本的に前年)の2つの未処置の予測変数も用意されます。 競合に勝利するモデルが選択されて、将来の値を計算するためにも使用されますが、この際、全てのデータを入力として使用します。 以下の図は競合の概念を示していますが、緑色の系列はオレンジ色の系列と青色の系列を使用してモデル化されています。(平均二乗誤差において)青色の系列が元の系列により近いため、オレンジ色の系列ではなくこちらが選択されます。
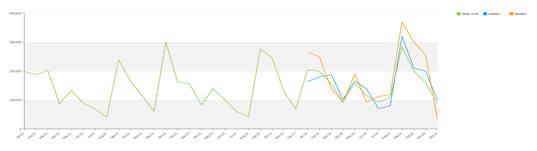
モデルが選択されると、将来に対してプッシュされ、予測を取得します。
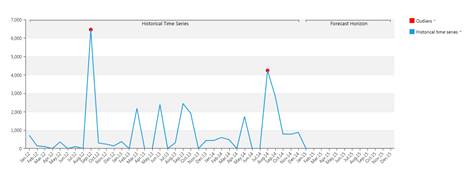
1.1.5 異常値
履歴データ内の変則的な値は、システムによって検出されます。これらを異常値と呼びます。 時系列の値は、モデルに対してその誤差が標準偏差との比較において3.5倍を超えている場合、異常値です。
1.1.6 共変量
共変量は、将来と過去の両方において定義された時系列であり、ある程度、観察された時系列に関連しています。 例えば、イースターエッグ販売者であった場合、イースターの月では系列が1として定義され、将来と過去の両方の外部の0は共変量です。 システムはこの共変量が系列に与えた影響を評価し、共変量が有用な場合にのみこれを将来にプッシュします。共変量に含まれた誤差が共変量に含まれない誤差よりも大きい場合、共変量は破棄されます。 共変量は、(1又はゼロである上記の例の値のような)ブール値又は別の時系列(例えば、販売されたアイスクリームの時系列を観察している場合、平均気温は共変量です)となる可能性があります。 共変量に対して将来の値を設定することは強制されません。例えば、特定の期間においてイースターエッグの店舗が閉店していても将来的には閉店しない場合、この期間にある事態が発生し、この事態は将来的には発生しないことをシステムに入力するだけです。
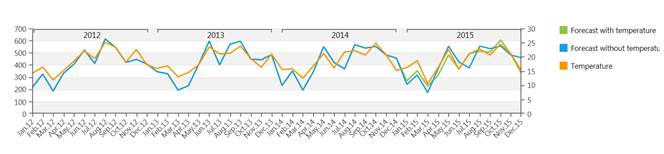
例1:
気温の共変量を使用した/使用しないアイスクリーム売上の予測(予測期間は2015年)
例2:
一部の特定期間におけるアイスクリームの特別価格(過去及び将来において定義されたブール値の共変量、予測期間は2015年)

例3:
ユーザのアイスクリームは、 過去に2回、月全体にわたって閉店しましたが、このような事態の再発は予想されません(ブール値の共変量は過去においてのみ定義されています)。 緑色の系列は共変量を考慮しますが、青色の系列は考慮しません。
必要なだけの共変量を適用出来ます。制限はありません。
1.1.7 予測の間隔
確信のレベルが Xであるとすると、予測の間隔 は、値のn間隔であり、ここで将来の値は確率Xによって設定されます。
言い換えると、90%の確信のレベルを設定する場合、システムは予測された期間に対して下限値と上限値を提供します。 将来の観察された値は、90%の確率の下限値よりも大きくなり、上限値よりも小さくなります。
例:
2015年度末において、値の90%が以下のグラフの青色の領域に該当していることが観察されます。

1.1.8 調整
複数のバージョンのキューブが存在する場合、予測的分析は各バージョンが個別のシナリオであると認識することで、これを処理します。
大部分の詳細なバージョンの予測の合計は、それほど詳細ではないバージョンの予測とは異なります。これは、対象のキューブが整合していないことを意味します。
このキューブを整合していないままにも出来ますが、調整を実行することも選択出来ます。
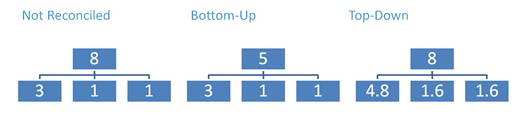
調整には、下降型 と上昇型の2つのタイプがあります。
· 下降型:それほど詳細ではないバージョンのデータを最下位のバージョンに割り当てます(Split&Splatに類似しています)。
· 上昇型:キューブを整合します。
1.1.9 誤差の統計
システムは異なるタイプの誤差を計算します。
MAE(平均絶対誤差):観察と予測の絶対値差分の平均です。 この測定値は計測に依存しています。
MAPE(平均絶対百分率誤差):誤差の平均絶対百分率サイズです。 この測定値は計測に依存していません。
MASE(平均絶対計測済み誤差): 未処置モデルのMAEとMAEの比率です。 これはスケールに依存しておらず、未処置モデルと比較して、予測がどの程度正確であったのかを測定します。 1よりも大きいMASEは、選択されたモデルが未処置モデルよりも低い精度で実行されたことを示します。1よりも小さい場合は、モデルが未処置モデルよりも高い精度で実行されたことを示します。
加重MASE全体: この測定は、様々な時系列の全てのMASEインジケータの加重平均です。
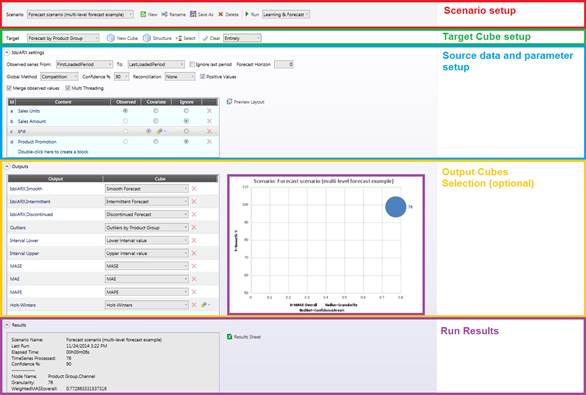
2.1 シナリオの設定
ここでは、左に配置されたドロップダウンリストから、どのシナリオを編集又は実行するのかを選択出来ます。また、シナリオを複製して名前を変更することも出来ます。 右に配置されたドロップダウンリストを使用すると、実行のたびに学習フェーズをシステムが実行する必要があるのか、あるいは予測フェーズのみでよいのかを決定出来ます。
初回の実行以前は、学習と予測の両方を実行することが強制されるため、ドロップダウンリストがグレイアウト表示されることに注意してください。 学習なしでシナリオを起動する唯一の理由は、これによってパフォーマンスが改善されることです。
2.2 対象のキューブの設定
ここでは、予測データが含まれるキューブを選択出来ます。このキューブは高密度の構造を備えている必要があります。ここから新規のキューブを直接的に作成するか、あるいはその構造を変更することを決定出来ます。 複数のバージョンを設定出来ます。 ここで選択を実行する場合、その選択内部のデータのみが考慮されます。時間の選択は設定出来ません。時間の範囲は次のセクションで決定されます。 また、予測によって事前設定する前にキューブ全体をクリアするのか、あるいは現在の範囲のみをクリアするのかについても決定出来ます。右に配置されたドロップダウンリストを使用して、適切なオプションを選択します。
対象のキューブは非常に重要です。実際に、このキューブは単にデータが挿入されるキューブであるというだけではなく、時系列の内容及びデータが読み取られるレベルも決定します。
例:
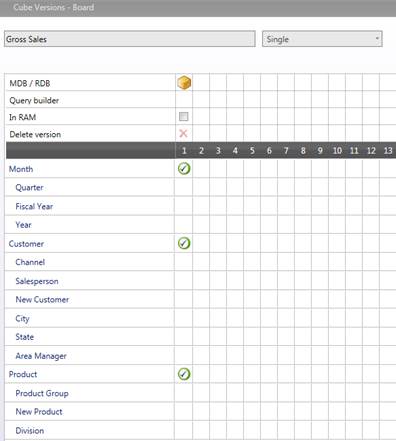
上記のような対象のキューブを使用する場合、ソースデータ内の顧客と製品の事前設定された任意の組み合わせは、時系列を示します。時系列の詳細は月になります。
2.3 入力データ及びモデルの設定
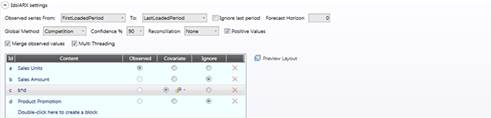
このセクションは、シナリオの設定において最も重要であり、ユーザの予測の精度は主に履歴データセットに依存しています。
2つのドロップダウンリストから、どの期間を観察するのかを選択出来ます。デフォルトの値は以下の通りです。
· FirstLoadedPeriod: 選択に与えられた最も古い値: この値は固有であり、各時系列に対して評価されないことに注意してください。
· LastLoadedPeriod: 選択に与えられた最も新しい値: この値は固有であり、各時系列に対して評価されないことに注意してください。
最後の期間のデータが完了していないと思われる場合、[最後の期間を無視(ignore last period)]チェックボックスにフラグを付けて、動的な方法でこれを除外することが出来ます。
[予測期間(Forecast Horizon)]:ここでは、予測する期間の長さを決定出来ます。デフォルトの0の値は、時間範囲の最後まで予測をプッシュします。
[グローバル方式(Global Method)]:競合を介してモデルを取得するか、あるいは2つの未処置の予測変数のどちらかを強制することを決定出来ます。
[確信(Confidence)]ここでは、上限及び下限の間隔を計算するために確信のレベルを決定出来ます。
[調整(Reconciliation)]:3つの調整のタイプのいずれかを選択します。これは、複数のバージョンの対象のキューブに対してのみ必要です。
[正の値(Positive values)]:一部の期間において負の結果を提供する全てのモデルを自動的に破棄するには、これにフラグを付けます。
[観察された値をマージ(Merge observed values)]:この設定がオンになると、履歴データは予測とともにキューブへコピーされます。
[マルチスレッド(Multi Threading)]:このフラグは計算の結果に影響しません。これは計算にマルチスレッド使用するのかどうかを決定するだけです。パフォーマンスの問題が発生する場合はこれにフラグを付けます。
次にソースレイアウトについて説明します。
ここでは、ソースデータとして使用するためにキューブ及びアルゴリズムを決定出来ます。
キューブ及びアルゴリズムは、以下のように設定出来ます。
· [観察(Observed)]:1つの観察されたキューブ/アルゴリズムのみが存在出来ます。これが予測を行う数量になります。
· [共変量(Covariate)]:必要なだけの共変量が存在出来ます。 共変量は、観察された系列にある種の影響を与える、過去及び将来の両方に値を持つ時間系列が含まれているキューブです(例えば、アイスクリームの売上を観察している場合、月ごとの平均気温を使用出来ます)。 また、共変量の最大ラグも決定出来ます。これは、特定の期間において共変量の値によって影響を受ける、前後する期間の最大数です。 システムは、予測に役立たない共変量を破棄します。共変量の使用を強制するには、2つの[歯車(gear)]アイコンからこれを決定することが出来ます。
· [無視(Ignore)]:アルゴリズムを作成するためだけにキューブを使用し、共変量又は観察として使用しない場合は、これを無視することが出来ます。
このレイアウトは、右上のボタンを使用してプレビュー出来ます。 これによって、行ごとに期間が挿入され、データを表示するためにキューブ/アルゴリズムを使用します。
2.4 出力
対象のキューブ内の予測の他に、予測的分析は大量のデータを出力します。 必要な場合、このデータを一連のキューブ内に挿入することを決定出来ます。
出力のキューブは、対象のキューブのように必須ではありません。これらの構造は、対象のキューブと同様になります(異なる構造が存在する場合、自動的に変換されます)。
[IdsiARX.Smooth]:このキューブは、対象のキューブのスライスであり、円滑の時間系列のみが含まれます。
[IdsiARX.Intermittent]:このキューブは、対象のキューブのスライスであり、断続の時間系列のみが含まれます。
[IdsiARX.Discontinued]:このキューブは、対象のキューブのスライスであり、中止の時間系列のみが含まれます。
[異常値(Outliers)]: このキューブは、様々な時間系列の変則的な値を使用して、過去においてのみ事前設定されます。
[間隔下限値(Interval lower)]:このキューブには予測の下限値が含まれます。実際の値は、確信レベルに等しい確率によって、間隔下限値よりも大きくなり間隔上限値よりも小さくなります。
[間隔上限値(Interval upper)]:このキューブには予測の上限値が含まれます。実際の値は、確信レベルに等しい確率によって、間隔下限値よりも大きくなり間隔上限値よりも小さくなります。
[MASE]:各時系列のMASEを含んでいるキューブです。期間のMASEは、その期間までの時間系列に対するモデルのMASEです。
[MAE]:各時系列のMAEを含んでいるキューブです。期間のMAEは、その期間までの時間系列に対するモデルのMAEです。
[MAPE]:各時系列のMAPEを含んでいるキューブです。期間のMAPEは、その期間までの時間系列に対するモデルのMAPEです。
[ホルトウィンタース(Holt-Winters)]:三重指数平滑化としても知られ、系列の三重指数平滑化を出力します。 アルファ、ベータ、及びガンマのパラメータをインターフェイスから直接的に設定出来ます。 [ホルトウィンタース(Holt-Winters)]は、ブロックエディタにおける予測時間関数の支配下のアルゴリズムであることに注意してください。
2.5 実行の結果
各実行の後、ユーザは実行時間、時系列の数、加重MASE全体に関する一部の統計を取得します。また、円滑の系列の数に対してMASEをプロットするグラフも取得します。
2.6 プロシージャを介したシナリオの実行
また、プロシージャから予測的分析のシナリオを実行することも出来ます。

ユーザは、プロシージャの選択又はシナリオの選択によってシナリオを実行するかどうか、また、学習と予測の両方ではなく、予測の部分のみを使用することを判断することが許可されます。