Clustering
1 Introduction
Board provides a feature for data clustering. It allowa to automatically fill a parent entity and its relationship to the leaf entity basing this process on a data mining algorithm named K-Means.
Board Cluster groups members of a certain entity creating relationships to a parent entity, the criterion will be decided given a set of cubes. Cluster will group the members that are more similar accordingly to the input cubes.
1.1 How to use it
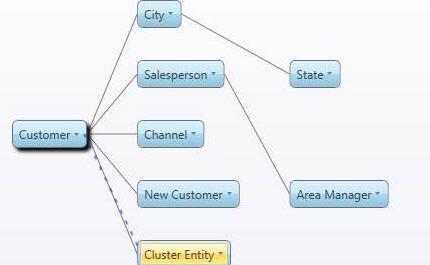
Create the entity that will host the parent members and relate it to the one we need to cluster.
Enter the Cluster section from the Database tab under the BEAM Icon.

Create a clustering scenario, you can select an existing one from the drop down list or create a new one.
![]()
· New: define the name for the new clustering scenario;
· Rename: retype the clustering’s name;
· Save as: save as another scenario;
· Delete: delete the scenario;
· Run: launch the clustering scenario.
The next part is about the entity we want to cluster and some model options:

Target: select the target entity which hosts the new distinct categories;
Source: select the source entity which will be grouped into distinct categories;
Paging option: It will group the source element in n different groups for each page. For example if I want to group the Customers paged by City, it will group for each city the customers that are similar in a certain way, so there will be the group that represents the best customers of that City, those customers may be not the best overall.
Reset: before to run the scenario, resets the previous clustering relationships;
Distinct group: when paging option is enabled it creates n entity members for each page;
Clusters: it define the number of clusters;
Group: define the custom name to assign to the target entity members;
Select: Source data will be filtered through this select
Now let’s see the source data, source data is a list of cubes/algorithms that will be used to understand the similarity of the entity members, for example if I want to cluster product by price, margin and sold units the cluster will group products taking care of all the three entities. Let’s see how we can set up the cubes.

· Attribute: data which is considered for clustering;
· Ignore: data involved for calculated fields but not adopted for clustering calculation;
· Labelling: it orders the groups by this observed series.
Last section shows results only , from here you can directly check the relationships.

A quick way to see cluster effects when we use only two cubes it’s to use Bubble-chart, in the sample below we created 5 cluster on 2 attribute cubes:
