The DataFlow action is a very simple yet powerful feature of Board which allows to implement sophisticated business models, without having to use a programming language.
To illustrate the capabilities of the Dataflow let's consider a simple example. Given the following cubes,
The Cost of Good Sold cube can be calculated by multiplying Quantity times Product Standard Cost, with the following dataflow:
Define a Layout where the blocks are
(a) Quantity
(b) Product Standard Cost
(c) Cost of Good Sold
and the target cube is (c) and the algorithm is a * b
BOARD checks the structural congruency before running the calculation: the Quantity and Cost of Goods Sold cubes are dimensioned by Month, but the Product Standard Cost cube is based on Year. Board automatically uses the Month-Year relationship to perform the operation between cubes with a different structure.
The calculation will take place in the following way:
”For each Month, Product, Customer combination, multiply the Quantity by the Product Standard Cost for the considered Product in the Year to which the Month belongs”.
The automatic use of relationships is not limited to time entities, and is applied to any hierarchical relationship defined in the database.
The following rules apply to any DataFlow calculation :
The evaluation of the formula always takes place at the aggregation level of the target cube. If one or more cubes involved in the formula have different structures than the target, they will be brought to a congruent level before the formula is evaluated, according to the following rules:
When a factor has one dimension that the target cube doesn’t have, it will be aggregated. For example: The factor cube is structured by Customer/Product/Month and the target cube by Product/Month. Before the calculation is run, the factor is aggregated for all selected Customers.
When the target has a dimension that a factor doesn’t have, the factor value is repeated for each member of the exceeding dimension of the target. For example, if one of the factors is Commission Percentage, structured by Salesperson/Month, and the target is Commission Percentage, structured by Salesperson/Product/Month, the same Commission Percentage value will be repeated for each Salesperson/Month for all Products.
When a factor is structured by a more detailed entity than the target, the factor is aggregated to the same level of the target. For example, if one of the factors is structured by Product/Month, and the Target is structured by Product/Quarter, then the factor will be summed by Quarter through to the Month-Quarter relationship.
If a factor is structured by a more aggregated entity than the target, the value of the parent occurrence is determined through the parent-child relationship. For example, one factor is %Royalty structured by Product Brand/Year, the target is Royalty Value structured by Product/Month, and there is a relationship ProductàProduct Brand. The %Royalty value of the Brand will be applied to each Product based on its Brand.
If the target cube has a sparse structure, the calculation takes place for the existing sparse combinations only. At least one calculation factor must be structured with either the same sparse structure as the target, or a sparse structure that is more detailed than the sparse structure of the target. For example, a sparse structure consisting of Customer/Product/Depot is more detailed than the sparse structure made up by Customer/Product.
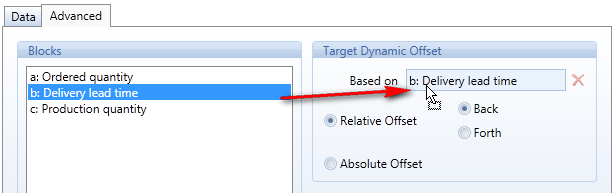
The Dynamic Offset is a function of the DataFlow used to shift cube values on the time dimension. The shift can be absolute, based on a specific date (Absolute Offset option), or relative (Relative Offset option), shifting values forward or backward for a given number of periods as specified by another cube.
The Dynamic Offset function is located in the Advanced tab of the setup.
Based On: set the cube that defines the offset .
Relative Offset: Shifts cube values forward or backward in time based on the number of periods specified in the cube set in the Based On field. The time shift can occur either forward (Forth option) or backward (Back option). To use the Relative Offset option, the Based On field must contain a cube containing integer values.
Absolute Offset: Shifts values to the date specified in the cube indicated in the Based On field. To use the Absolute Offset option, the Based On field must refer a cube containing dates (a cube of type Date).
For a complete list of the Actions and related syntax please open the Data Flow Action Reference Document.
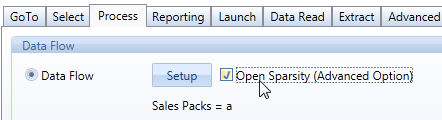
The Dataflow is able to open new sparse combinations, if the following conditions are met:
- the Dataflow Layout has only two cubes, one in block (a) which is the source cube and one in block (b) which is the target cube,
- the algorithm must be b=a
- the source cube must have not use any Reference function such as Referto, TotalyBy.
- the source cube must have a sparse structure and the target cube must have a sparse structure which is made of the same entities plus one or two entities more (also in sparse).
When the above conditions are met, the check-box Open Sparsity can be enabled.
The sparse combinations of the target will be the same as those of the source multiplied by the selected members of the additional entity part of the sparse structure of the target.
A dataflow opening sparse combinations should be configured with caution and awareness because if misused it can easily create extremely large sparse structures with millions of combinations, impacting negatively the entire database. Generally such a Dataflow should be preceded by a select action that limits to a few elements the entity over which new combinations are created in order to avoid inadvertently creating a huge and unwanted number of sparse combinations.
Lets consider the following example:
- cube (a) Revenues, dimensioned by Month, Customer, Product, where Customer and Product are sparse,
- cube (b) Profit and Loss , dimensioned by Month, Account, Customer and Product where Customer, Product and Account are sparse.
A typical use of this new function would be to open a sparse combination on the account line "Direct sales revenues" for customers belonging to the Channel="Direct customers" (supposing that Channel is a parent entity of the Customers entity) and open other sparse on the account line "Indirect sales revenues" for the customers of another channel, for example "Indirect customers".
This can be done with the following procedure steps:
- Step1: Select Channel="Direct customers"
- Step2: Dataflow Layout
(a)Revenues
(b)Profit and Loss, algorithm b=a
with option "Open sparsity"
- Step3: Select Channel="Indirect customers"
- Step4: Dataflow Layout
(a)Revenues
(b)Profit and Loss, algorithm, b=a
with option "Open sparsity"
The execution time of a single data-flow depends form a lot of factors : the structure of the Dataflow, the structure of the info-cube, the size of the info-cube, the size of the selected. elements of the info-cube dimension.
It is possible to evaluate how much fast a Data Flow is executed from the Analysis of the Logs : the Log details which algorithm type is being used.
Board data-flows may use different types of algorithms. The most popular are HBMP that is the fastest, and Cellbased which is the slowest.
The following rules must be followed to obtain HBMP calculation algorithm, therefore the fastest possible execution time.:
1.The target cube must be the last one of the dataflow layout and it has to be at least at block b. (i.e. c=b*a can run in HBMP+, a=b*c won't run in HBMP)
2.Cubes structures must be as close as possible, if the target cube structure is a subset of one of the source cube's structures the dataflow will be an HBMP, if it's a subset of the superset of all the structures of the source cubes you will have a Pattern algorithm
3.Sums and differences must not be in the formula: c=a+b is not HBMP, c=a-b is not HBMP, c=a*b may be HBMP depending on the cubes structures. (basically only * and / operator can be used to have HBMP)
4.Refer to, Total by, Rules, should not be used to obtain HBMP.
5.The dataflow Layout contains only cubes (no intermediate blocks with algorithms)
6.The cubes are only of numerical data types (no text, no dates)
Data Flow: Time Function are applicable in the Data-Flow command if Info-cubes with 128 bit Sparsity are involved. It is still not supported with 128 bit Info-cubes Dense Structure.