It is now possible (optionally) to define the parameter MaxItemNumber for entities used in a cube structure. Similarly to the MaxItemNumber parameter of BOARD version 10, this parameter sets the maximum number of members (items) that an entity can contain. If you are a BOARD 10 developer, note that there are many fundamental differences as described below.
MaxItemNumber
It is an optional parameter for all entities.
By default, its value is set to zero (“auto”) which means that the BOARD engine defines its value automatically based on an internal optimization algorithm.
It is only relevant for entities that are used in a cube structure definition. For entities that are used for on-the-fly aggregations, this parameter is ignored. For example the MaXItemNumber of the entity City which is a parent of Customer is ignored for cubes by Customer.
It should be set manually by the database designer only in exceptional cases: when the entity is used in a cube with more than four or five dimensions and number of members of an entity is known to increase strongly in the future.
It is possible to manually change the value without clearing the entity as was necessary in BOARD version 10.
When an entity is used in a cube structure, a MaxItemNr is automatically calculated for that entity in that structure, using an internal algorithm that optimizes compression and performance. The calculation of the MaxItemNr occurs only after entities have been populated with members (isn’t computed for empty entities) and at the first load of data in the cube (i.e. it is not defined as long as the cube is empty).
The algorithm analyses the entities that are part of the cube structure and depending on the numerosity of entity members, it assigns a MaxItemNr to each entity in that structure. The same entity may be assigned a different MaxItemNr for each different structure where it is present. The optimization therefore relies on the current number of members present in each entity that is part of a structure.
In order to automatically obtain the best possible optimization it is a good practice, before loading data in cubes, to load your database entities with a significant set of data that truly reflects the numerosity of each entity (not a subset of data) and then load the cubes data.
When it is not possible to fully load the entities, for example because only a subset of data is available, or because some entities are known to grow significantly over time, then it recommended to manually define the MaxItemNr for those entity. The value of the MaxItemNr should be set to the estimated number of entity members. Note that by default, BOARD will automatically add 20% to the given MaxItemNr so that the entity can grow 20% in excess of the given number without compromising the data integrity.
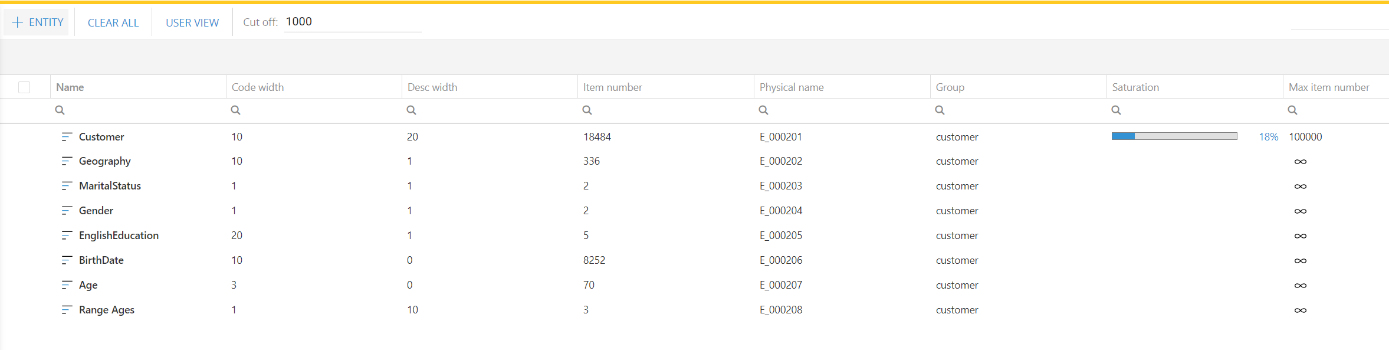
Saturation%
The ratio between the number of members of an entity and the MaxItemNr is the Saturation%. The Saturation% is displayed in the Entities definition (see picture below) and it should always be less than 100%.
The MaxItemNr and Saturation% depends on the number of entities in the structure, therefore an entity used in several cubes having different structures will have a different Saturation of each structure. The cubes where the entity is used and the value of the Saturation% is displayed in the Analysis tab of the Entity definition.
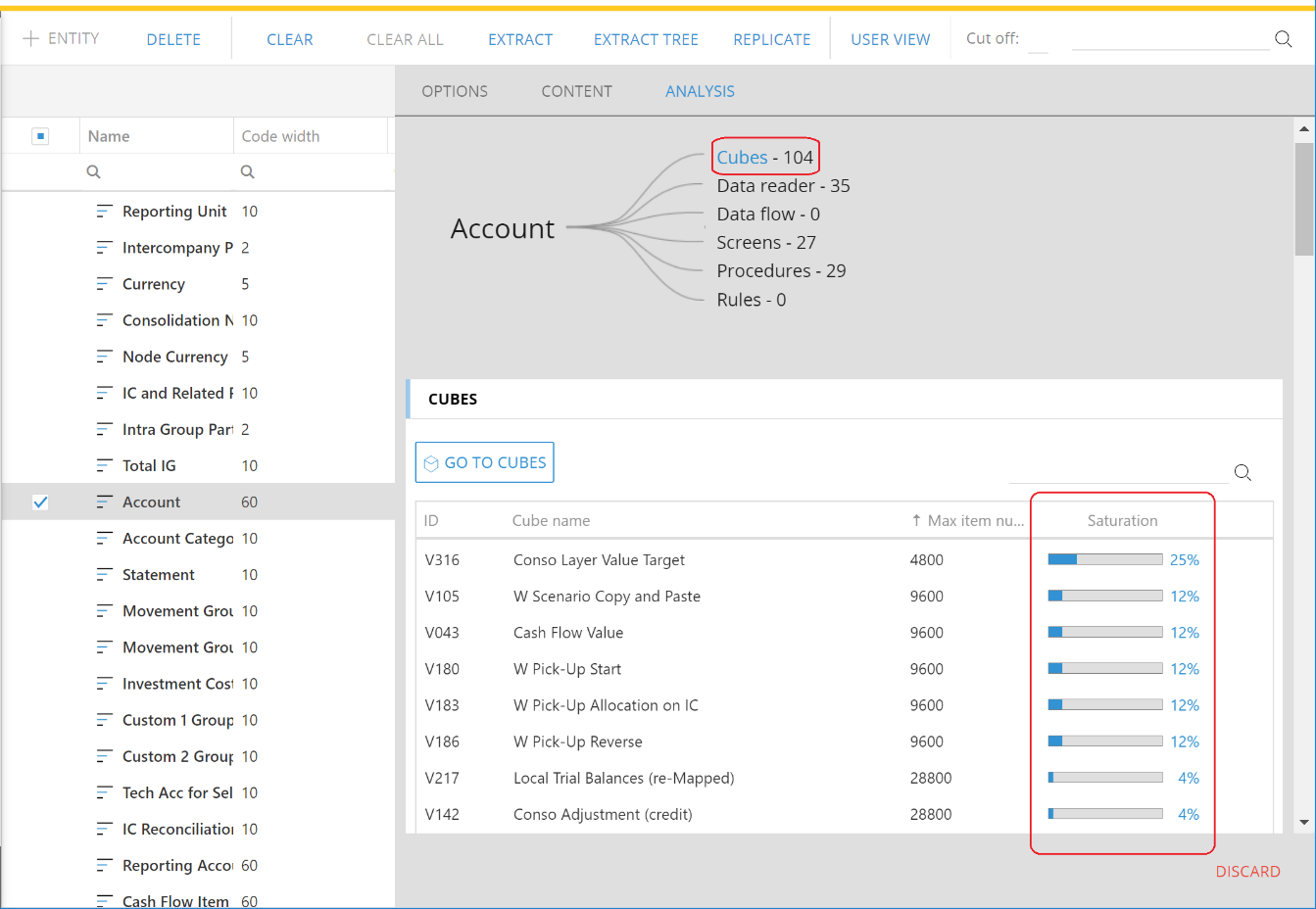
In case the saturation exceeds 100%, the integrity of data in the cubes is no longer guaranteed therefore it is necessary to clear the affected cubes then do one of the following:
verify that the MaxItemNr set to “auto” (if not, set it to zero) and simply reload the cubes.
in case the entity cardinality (number of members) is estimated to grow significantly, set the MaxItemNr manually to a value that is equal to the estimated future cardinality. Then reload the cubes.
In case the saturation of is near 100% and it is estimated to grow, it is recommended (before the saturation exceeds 100%) to perform one of the following actions:
verify that the MaxItemNr set to “auto” (if not, set it to zero) and then run a Db Optimize (note: set the database in maintenance mode before running the Optimize).
in case the entity cardinality (number of members) is estimated to grow significantly, set the MaxItemNr manually to a value that is equal to the estimated future cardinality then run a Db Optimize (note: set the database in maintenance mode before running the Optimize).
Note that the MaxItemNr can be changed manually in any moment, to make the change effective, either cleared and reloaded the cubes using the entity or simply run a DB Optimize.
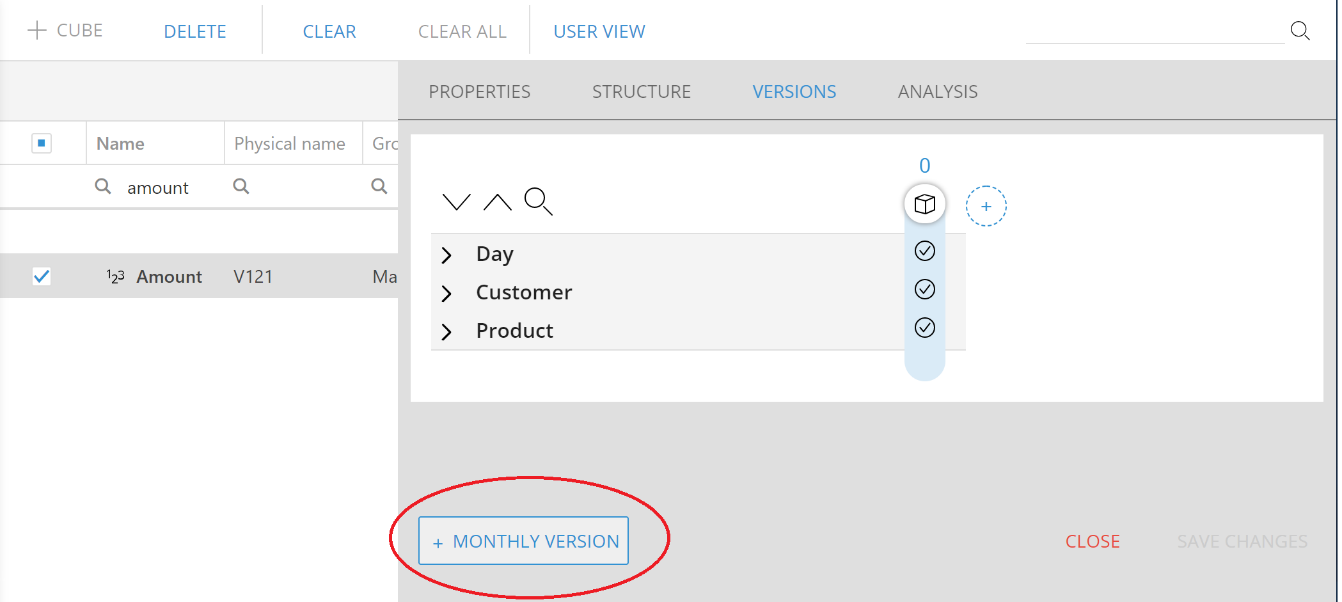
It is now possible to manually define pre-aggregated versions of a cube in order to improve reporting performance.
To create a pre-aggregated version, open the cube definition, go to the Versions tab, click the Add version (+) button and set the level of aggregation of the version by choosing entities that are more aggregate than the detail version (version 0) or omitting one or more entities of the detail version. Click Save Changes to confirm, the new version is saved and aligned (i.e. populated with data from the detail version).
Pre-aggregated versions can only be added if the detail version is populated with data, it can’t be defined if the cube is empty.
When defining a new version, it is normal that some of the entities of the detail version may be pre-selected in the pre-aggregated version and can’t be removed. This applies to entities, generally those with a low number of members, for which a pre-aggregation would not provide performance improvements because the system is already optimized for aggregating that dimension.
If a pre-aggregated version is equal to the detail version but with one or more entities omitted (one or more dimensions less) then the alignment of data is always automatically maintained by the system (unlike in Board 10 and earlier versions).
If a pre-aggregated version uses an entity which is a parent of an entity in the detail version, then the alignment of data is automatically maintained only after a DataReader or a Data-entry on the detail version. If a cube containing this type of version is calculated through a DataFlow, then it is necessary to add a Cube Align action after the Dataflow calculation to reconsolidate data.
To remove a version, click the Delete All Versions button. Note that it is not possible to selectively remove one version only.
Pre-Aggregates on Time Dimensions
On cubes dimensioned by Day, it is possible to add one pre-aggregated version by Month by clicking the Monthly Version button. This version will have the same structure of the detail version except for the day-to-month aggregation. Other manually defined versions must all use Day as time entity.
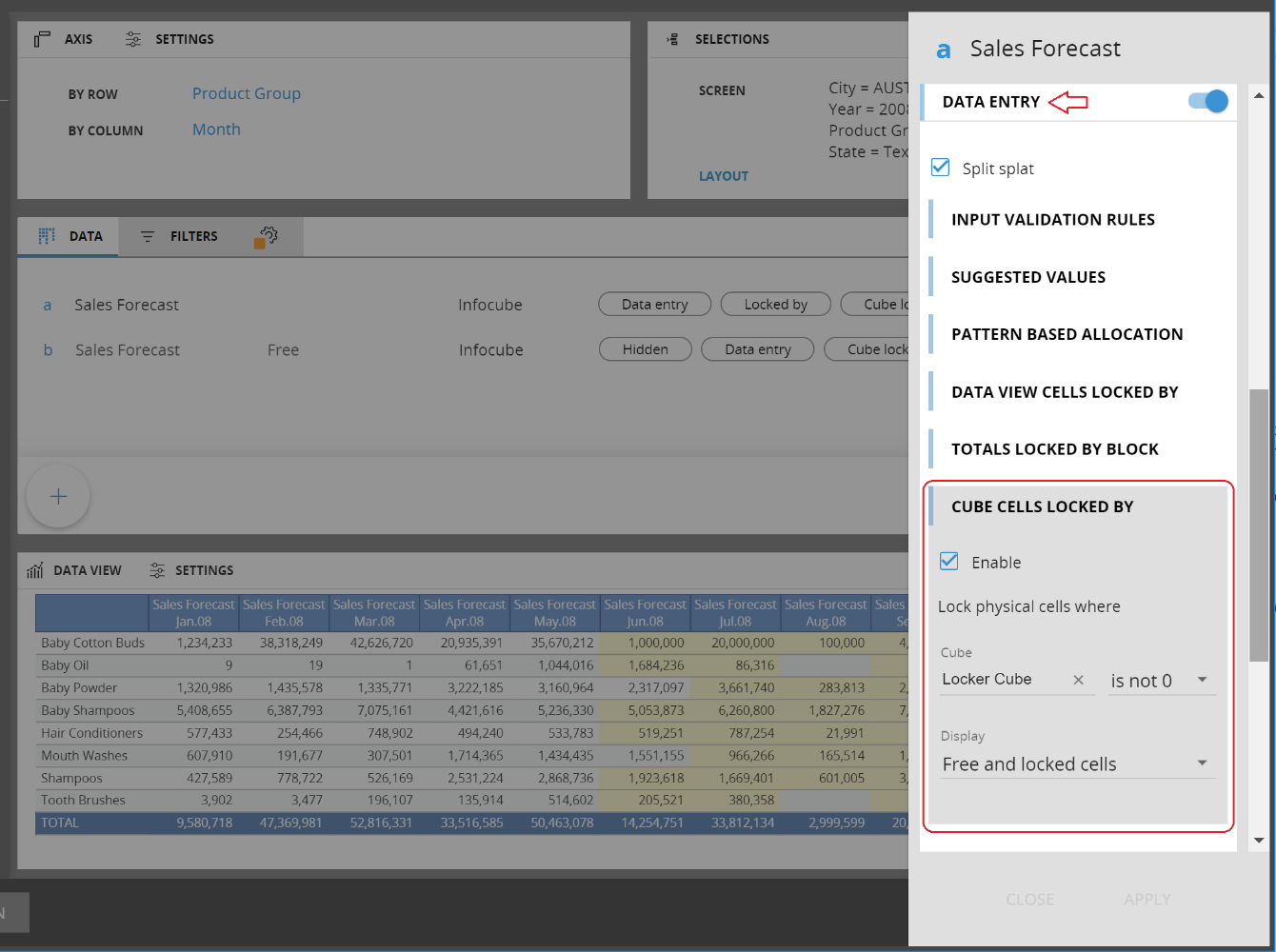
The DeepLocker extends DataEntry functionality of the DataView object with the ability to lock DataEntry on some cells of a cube based on the value contained in another cube of the same structure or a more aggregate structure. This new function is similar to the existing LockBy (or Loack&Spread) function however it works at the physical level of the cube, therefore it allows to set a lock on cells at a more detail level than the DataView level.
For example, using this function it is possible to create a Dataview at Region and Quarter level and set a data-entry lock on one or more Cities and Months. When the user enters a value at Quarter/Region level, the value is allocated down to the physical cells proportionally however all the physical cells corresponding to locked Cities and Months remain unchanged (the new value is proportionally allocated on the free cells only).
To configure the DeepLocker function, go to the DataEntry section of the properties of a data.entry cube of your DataView and set the following parameters:
Enable: tick this check-box to enable the feature
Cube: select a cube containing that determines the locking/unlocking of cells
is not 0 / is 0: set the logical expression that determines the lock condition
Display: select Free&Locked cells to return the total value of the data-entry cube or select Free cells only to return the total value of cells that are currently not locked.
This version includes all bug-fixes and minor changes released in version 10.6.1 and 10.6.2, please refer to the online documentation for details. Several important fixes and enhancements have been applied to the DataFlow engine providing now
support for more complex calculations involving cubes of different structures, with multiple functions applied such as Time Functions, Refer to and Total by or Offset
greater control on the settings of the Calculation Domain in order to force computing new cells when desired.
Below the detailed list of fixes included in this version.
Integration of the web server with an architecture with a reverse proxy has been reviewed and improved
Transition container - Label does not fill all container as expected
404 not found ../Content/images/....text/plain by opening screen with drills
Add member through an ATO: description field is disabled
Excel Add-in: BCUBE formula is now supported
Data Entry on BLOB cube: case of Red Toast at Save when a trigger is present.
Case where was not possible to create cube versions on certain databases.
Case where it was not possible to modify the structure of a vector cube.
Case of malfunction of the side menu occurring after renaming a Capsule.
Case where monthly version cannot be created.
Wrong message after changing of cube structure
Case of exception after changing cube type
Change of cube data type: warning is missing
Chat : attachments (link to screens) are not sent in the message.
Clear all versions shows message wrong message
Layout configuration: incorrect order in the column appearance section
Case of content of the Dynawrite appears empty.
Total By dialog box : missing scroll-bars
Create version: case of wrong message appearing when creating a new version.
Creating new BLOB cube: case of wrong extension repeated.
Cube Verify: values are not updated when selecting a second cube after a first execution.
Cube Wizard: RDB Query doesn't show data reader correctly
Cubes: Version not shown correctly under the properties tab
Custom Time Entity : entity mask input was missing
Data source configuration for ROLAP - data reader should not be editable from connections
Dataflow: support for Target Dynamic Offset / Relative
Dataflow: case of calculation from text cube to numeric cube
Dataflow: malfunction on calculation with ROLAP cube of type Text.
DB migration: case of database that could not be migrated due to exception.
Delete all versions does not work at first attempt if immediately run after unloading the DB
MS Edge: resolved cases of resize issues in the ETL configuration.
Extract: case of a malfunction causing the Extract version action to fail.
BEAM Forecasting: the calculation of the Forecast was not written to the cube
Go to Procedure could open a blank screen.
Heatmap: cube selection displayed twice in the block properties
Heatmap - If heading is defined, it could appear duplicated on floating panel
If Cube name is too long, name is truncated on protocol configuration
If Cube order is changed on user view, it is not applied on layout configuration list of cubes
Procedures. Paste button not appearing after clicking Add Step.
Procedures: The Remove Select on Tree shows also the standalone entities
Label object properties: impossible to reset the Action Value after it has been set
Print: Comments could be duplicated in the Print area.
Procedure: Copy/Paste could lose the Selection
Procedures: cases of errors causing "REFRESH SCREEN" to stop working.
QuickEdit drop area: difficult to change entities if not placed on same row
ROLAP configuration shows previous DataReader protocol if right side-panel is not closed
Rules: import a rule does not auto-refresh the grid file until closing right panel.
Run Procedure : cloud not run nested Procedures (saved in a Capsule).
The character " used in a Capsule name caused an error (Red toast).
Search temporary cube shows html tags on the page.
Select on layout does update correctly the “Issues” messages.
Layout Summary algorithm: Type is not shown on newly created DataView when used
Summary of cube creation - group and data type are cleared after click save changes
Extract and Reload Text Cube with carriage return
Export Excel with formulas containing ";"
Dynamic Selection Based On Cube... with option Latest Period
Transport: Package not created if name is already in use for a different package
Error of the Show value on Label with a Layout
Changes in data reader mapping not kept after adding where condition
New cubes created under noname group
Custom time entities cloud be displayed twice in the layout editor
Minor regression on Lock&Spread data entry mode
Capsule Log : Different/Wrong Format of the log file
Case of Entity Names being truncated
Case of Datareader not running after the first run
DataEntry with Flatten mode: cases of error changing grand total with grouping
Data reader SQL cloud ignore changes on edit.
Interactive selection on time entities NOT present in the db
Entity uploaded through ascii DR - if only code is loaded, not possible to search.
Data Reader with only headers gives an error
Cannot edit the nested procedures
Cloud not set the Entity default row template
Procedure step IF-THEN-ELSE : does not display the Details
Chart: editing properties with “mixed values” resets the chart and series type
Error creating Capsule procedure if DB Access Mode is READ and Write
Selector object: case of malfunction when using Transparency on Selectors
DataView: Block Format and Template only partially working
QuickEdit: missing scrollbars and sorting
Hide screen list and direct URL to a capsule screen
Screen selection lost when going back to screen by using browser back button
Relationships scan: Analyze Top Down causes exception
Entity Editor - ATO - New members can’t be added to an empty entity
Text Cube (RTF) not displayed correctly
Cases of errors on Create PDF from Presentation
Cloud not run a procedure if in a capsule contained in a folder with the “&” character.
Data entry on relationships cloud fail
Layout Option "DillToScreen" is applying Screen select from Source screen
Master layout with groups collapsed not rendering correctly
Chart export to Excel loses selection from master layout
TK-57792 B11.2 - Change font color on subgroup of sitemap menu leaves arrows black
Case of the “Send to” action ignoring the selection
Transporter does not transport Rolap cube settings
DataView: case of “Display code, desc, c+d“ not working
Dynamic drill to screen setting within a layout is not saved (from algorithm)
Custom time entity: it is not possible to append new members
Export to Excel without selections
Toolbox loader remains open after trigger on data entry with disable refresh after execution
TreeMap: Cases of Red Toast when drilling on a white area
TreeMap - Export to Excel as flat data table causes Red Toast
TreeMap - Red Toast when drilling-down on a total equal to 0
Treemap: case of configuration of size and color of panel not being displayed
Cube Versions : selecting multiple cubes causes loader to remain indefinitely
Case of db where cube versions could not be created.
Lock by could cause 100% CPU saturation when ShowAll rows is enabled
The BOARD Server Installer package has been updated. The new installers include a fix for
- A malfunction on SAP Datareader.
- A malfunction on Datareader when entity code terminates with a dash (-)
- A malfunction in the Data flow calculation has been fixed.
- File extraction: increase the performance of writing to network drivers.
If you downloaded the version prior than 6th March 2020, please download it again and update the BOARD installation on your environments.
The Full BOARD installer packages have been updated. The new Patch versions contains a set of new features and bug fixing. All the details are listed below.
The Select Bookmark is a new feature introduced on the web application. It allows the users to create their own library of different selects that can be saved and reused in the capsule screens. So the users can play with the selections through selectors and screen selections (when it's allowed) and then save it. Each saved selection is called Bookmark. Each user can create its own bookmarks that are available just for himself.
The bookmarks can be created and used through the application menu as per the image below:
Clicking on Select Bookmark the configuration pop-up window appears:
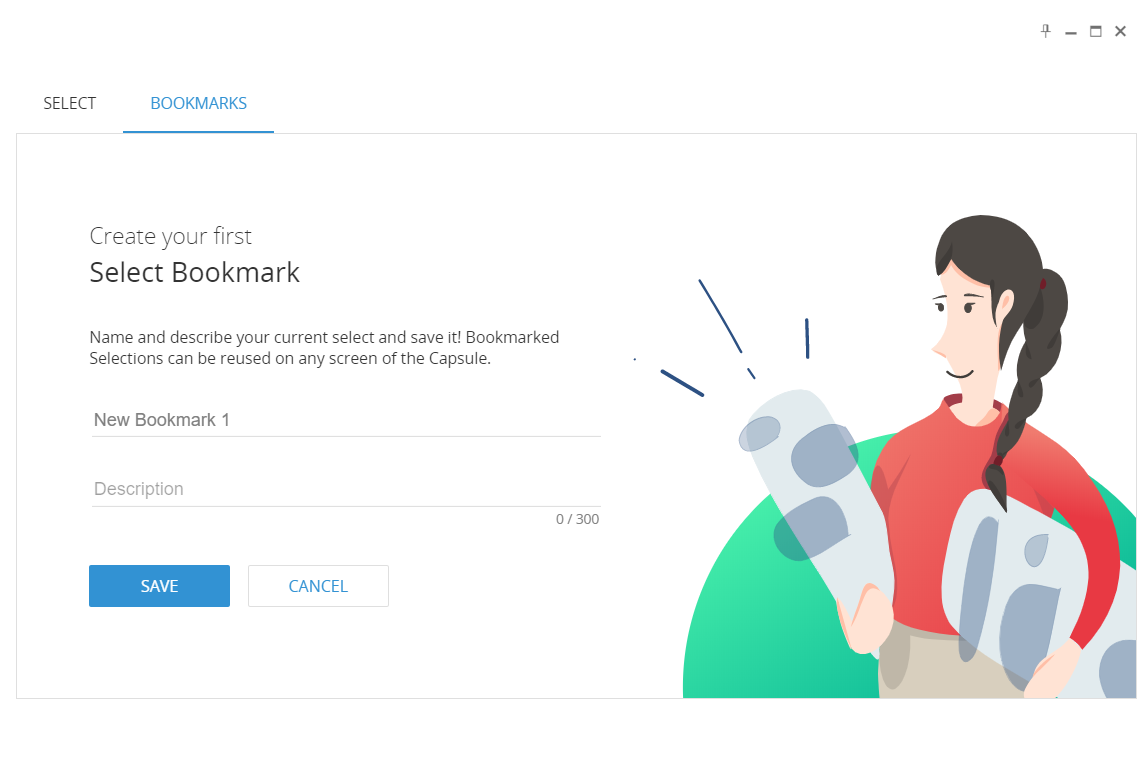
It is now possible to give a name to the specific select bookmark, define a description of it (maximum 300 characters per each description) and then save it.
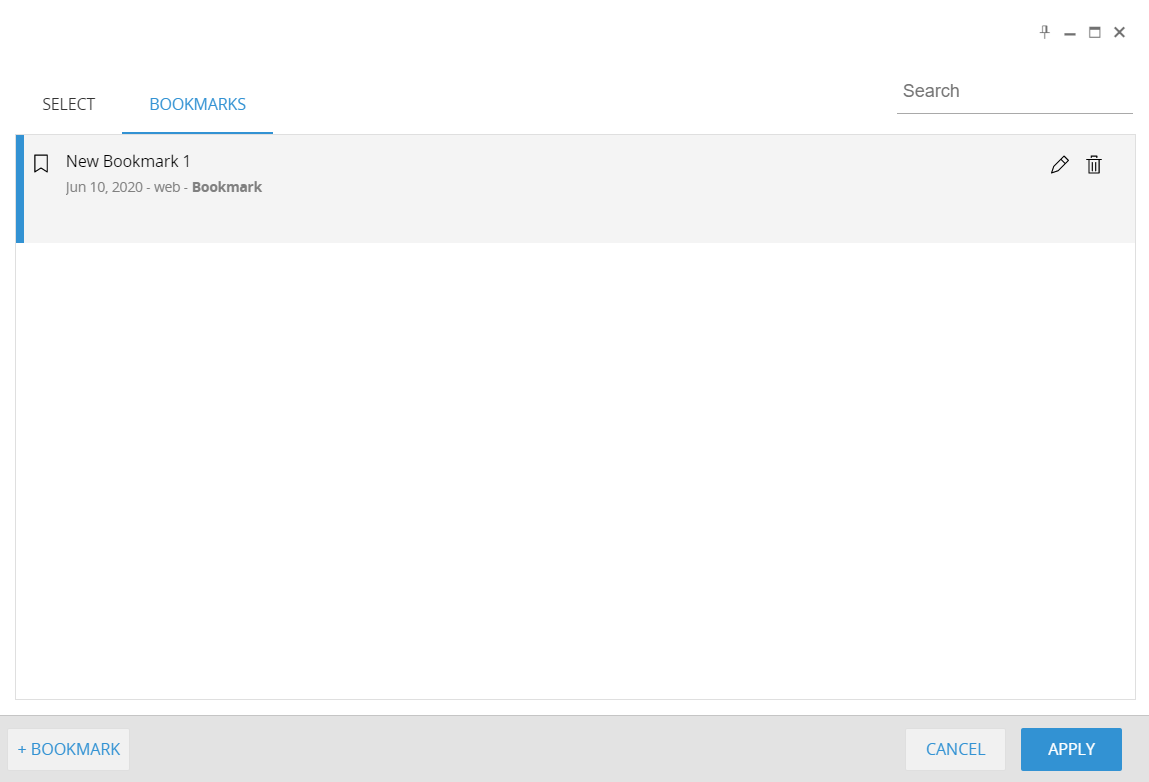
Once it is saved, the list of the available bookmarks is updated with the new bookmark. It is possible to edit the name and the description and delete the saved bookmarks through the pencil and recycle bin icons on the right side of the bookmark object.
It is possible to add new bookmarks clicking on the +BOOKMARK button.
It is possible to apply the bookmark to the current screen just double clicking on the bookmark. It is also possible to apply the bookmark to the current select window selecting the bookmark and clicking apply. Then the current select is updated appending the bookmark selection to the current select. The select bookmark supports the multi database option.
The My Screen View is a new feature introduced on the web application. It allows the user to save a modified view of the capsule screens. The users can modify layouts through the layout editor and the quick edit layout, drills configurations and pager synchronizations in play mode and the save the custom view.
The custom view can be recalled from the user. It is possible to save a single view per each screen and each user have their own views available.
The My View function is available on the web application menu as per the image below:
Clicking on My View the configuration pop-up window appears:
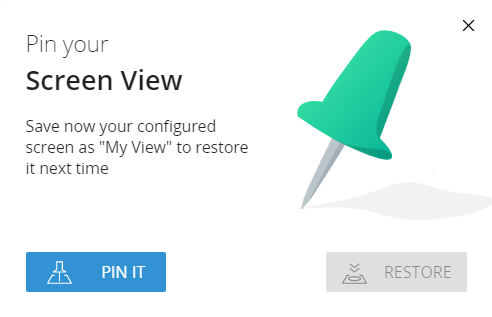
Clicking on Pin It the modified view of the screen is saved and available for the user.
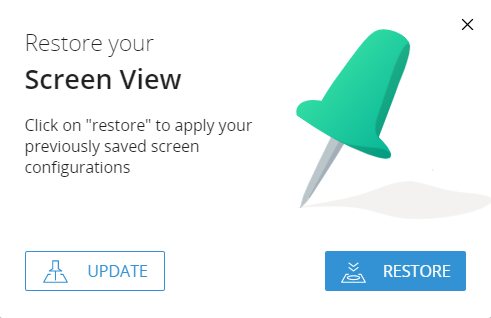
The restore button apply the pinned view. The Update button will save and overwrite an existing saved view.
It is possible to sort the columns of a dataview layout based on the column total value of a block. The sort by column is available only on the DataView Toolbox. It is available under the Filter settings of the Layout Designer. The Keep Top and Keep Totals Options are available for the sort by column.
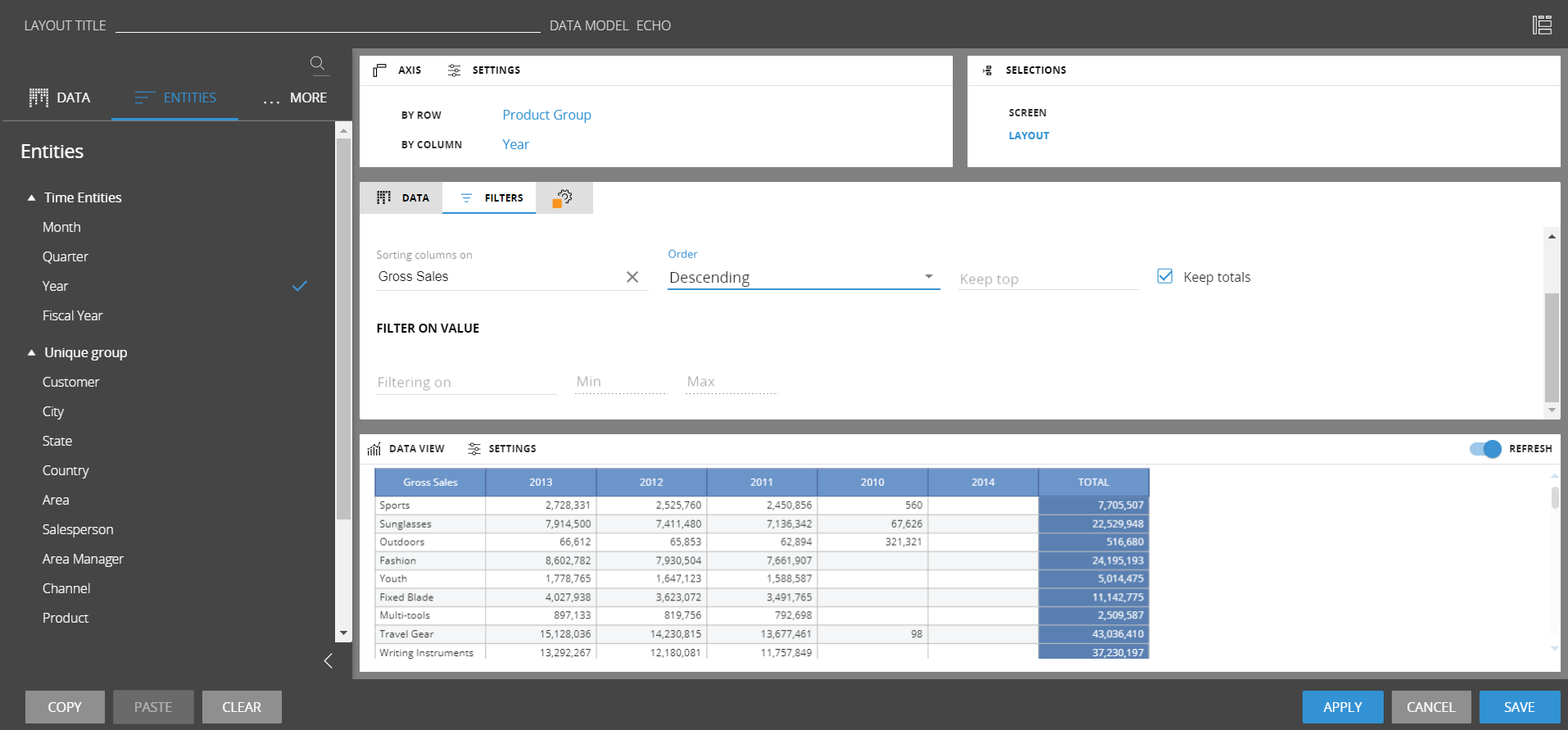
The column sorting is available only for layout with maximum 3 entities by column. It is not applied on blocks with the detail by option enabled.
Defining an host as an http/https address the add-ins will connect through the standard ports for those protocols and not through the 9700s ports. The protocol needs to be specified in the host configuration as per below:

It is mandatory to have the BOARD WebAPI Engine deployed on the server to use this configuration because the web Engine is acting as a proxy for the communication with the BOARD Engine. If this configuration is used, it is not required to open the 9700-9710 TCP ports because the communication go through the standard http/https ports. When this host configuration is in use, the Windows Authentication is not available for the specific host configured in the connections.
This new version contains enhancements on the vertical layout settings:
the alerts are now supported on the web
the block formatting is now supported
There are also new general enhancement on the web client:
A search field is now available on the extract cube procedure step.
It is now possible to define a default template for the entity formatting.
It is now possible to navigate directly on a nested procedure recalled on a call procedure step when the user is working in the procedure designer.
Below the list of fixes included in this version. If not specified, all the client-side fixes are applied to the web client only.
If a text cube contains a string with a negative number only, the export to excel will consider the sign
The transporter is also creating new Groups for the rules once is launched
Space characters set as a first character on label captions are considered on the caption in play mode
A malfunction that was preventing the pager object to keep the right sizing in play mode has been fixed
Send To action name supports now Japanese characters
An issue that was preventing the deletion of a Monthly cube version has been corrected
The add to presentation function is not showing anymore screens that belongs to capsules with the hide screen list enabled
A malfunction that was occurring removing the flag on a cube variance has been fixed
A malfunction on the concurrent update of presentations has been fixed
An issue on the create printable report feature executed on a screen with a printing area and the repeat by function enabled is now fixed
An issue that was preventing the visualization of cubes without any group assigned has been fixed
A malfunction that was preventing to execute the clear all variances function has been corrected
Procedures are now alphabetically sorted when displayed on lists (such as procedure lists on the button action)
The spacebar key can now be used in the search fields on the procedure steps such as clear cubes
The web tree-map is now showing the entity details if the detail by is enable on a shown block
A fix for the display of long database name in the data-model designer has been developed
A malfunction while setting the Limit drill down entities and using the drill anywhere has been fixed
An issue that was occurring on a specific layout configuration with the layout select in keep mode intersected with a screen selection has been fixed
A malfunction on the color of the Waterfall Grand Total has been fixed
A malfunction on the export rule from the web client has been fixed
An issue that was preventing to read fields with the dash (-) symbol as a last character has been fixed
The menu object is now inactive when the user is in design mode on the screen
The dataflow algorithm detail is now shown on the log section of the web application
When data entry is saved through a procedure, if the data entry has been made on a dataview with scrollbars, the focus of the dataview is kept after the refresh
A malfunction that was causing an unexpected logout action while the same user is trying to login from 2 different locations but typing a wrong password has been resolved
A malfunction that was preventing to correctly restore huge databases has been fixed
An issue that was preventing to search through a data entry with suggested values based on entities with more than 300 members has been fixed
A malfunction on SQL datareaders mapped on columns that contain the word "Measure" in the name has been fixed
An issue that was not showing the relationships definition when the capsule name contains the & character has been fixed
When the hide screen list property is enabled it is not possible to see the screens from the capsule hamburger menu
An issue on the credentials using the LDAP authentication has been fixed
An issue on the data entry action on a text cube defined on a layout inside the expander container has been fixed
The calendar options on the custom time entities are now visible on the layout editor time function configuration
A malfunction on the responsiveness of the label shapes has been fixed
An issue that was preventing to drill anywhere when the license level check param is set to Medium has been fixed
A malfunction on the export to excel with selections has been fixed
An issue that was preventing to export to excel layouts containing formula with the character ";" has been corrected
A malfunction that was preventing to configure and correctly use the dynamic drill to screen feature has been fixed
An issue with the configuration of fonts and borders on the cell templates for the entities has been fixed
A malfunction that was preventing to expand dataview collapsed groups when the master layout option is enabled has been corrected
An improvement of the transport action for the data-readers objects has been introduced
The corporate identity designer has been fixed. This is valid only for the Win Client
When a new selection is applied on a chart through a dataview master layout on the same screen, the export to excel function triggered on the chart will consider the new selection
It is now possible to perform data entry on grand totals on dataviews with the flatten mode enabled
When changing the color of the subgroups of the sitemap, this modify is reflected on the "arrows" of the menu object
A malfunction in displaying RTF content on a text cube has been corrected
The drill down to screen function with the option Go To Screen enabled is preserving the selection of the target screen
A fix for the usage of the transporter with ROLAP cubes has been introduced
The entity editor object can be set on empty entities
An enhancement on the cube version visualization has been introduced in the data model designer. When cubes have many dimensions in the structure, it is possible to mouseover to see the details
Procedure If-Then-Else steps show now the details on the procedure steps list
When the Hide screen list option is enabled on a capsule it is not possible to navigate through direct URLs. It is possible if the screen was already opened from a user in the same browser session
Extract and reload of text cubes is considering the carriage returns
A malfunction that was showing twice the custom time entities on the layout editor has been fixed
A wrong visualization of the max item number on the time entities has been removed
An enhancement on the chart type and chart series type has been introduced
A correction on the show value applied on the label object has been introduced
Selection are kept when navigating back and forth with the browser arrows
A malfunction on a specific data reading process that was breaking a layout visualization has been fixed